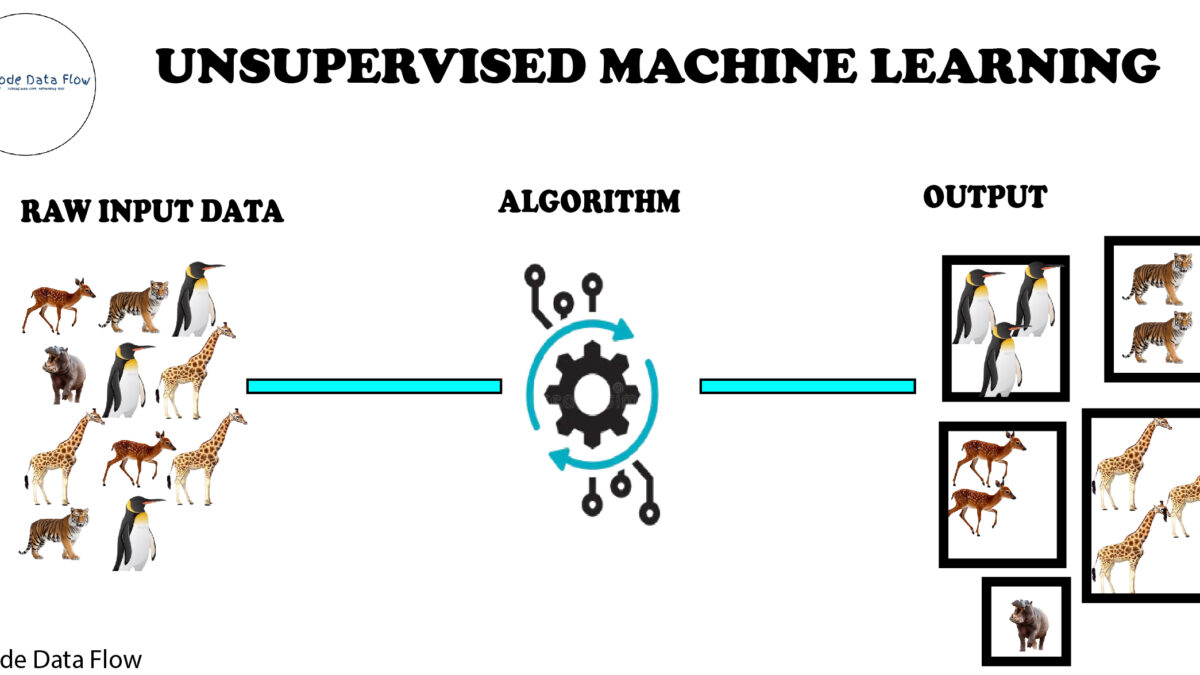
UnSupervised Machine Learning
Unsupervised learning is a type of machine learning that works with unlabelled data and helps discover hidden patterns without human input.
What is UnSupervised Machine Learning?
One area of machine learning that works with unlabelled data is called unsupervised learning. Unsupervised learning algorithms are entrusted with identifying patterns and correlations within the data without any prior knowledge of the data’s meaning, in contrast to supervised learning, where the data is labelled with a certain category or consequence. Without any human involvement—that is, without providing our model with output—unsupervised machine learning algorithms uncover hidden patterns and data. The training model finds the groupings or patterns on its own using just the values of the input parameters.

How Unsupervised Machine Learning Works
Finding patterns and links in unlabelled data is how unsupervised learning operates. The algorithm must identify these patterns and links on its own because the data is not labelled with any predetermined categories or outcomes. Since it can provide insights into the data that would not be seen from a labelled dataset, this can be a difficult but rewarding undertaking.
Example – Figure A:
“These patterns are revealed through unsupervised machine learning algorithms.”
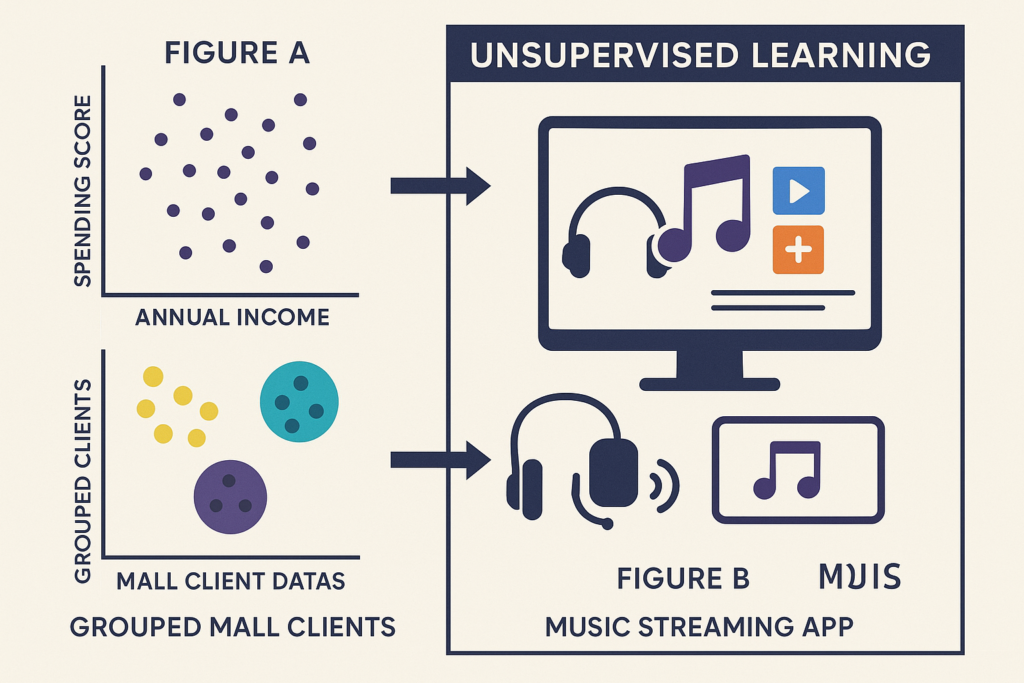
The dataset in Figure B is a Music Streaming App dataset that records user behavior—such as songs played, skipped, liked, and playlist additions. The app doesn’t require users to label their music preferences manually. Instead, using unsupervised learning techniques like clustering, the app can automatically segment users based on listening patterns and recommend personalized playlists or new songs tailored to each user’s taste.
The following is the input used by the unsupervised learning models:
Unstructured data may include unknown data, missing values, or noisy (meaningless) data.
Unlabelled information There is no intended value (output) in the data; just a value for the input parameters is there. Compared to the labelled one in the Supervised technique, it is simpler to gather.
Unsupervised Learning Algorithms
There are mainly 3 types of Algorithms which are used for Unsupervised dataset.
- Clustering
- Association Rule Learning
- Dimensionality Reduction
1. Clustering Algorithms
In unsupervised machine learning, clustering is the process of assembling unlabelled data into groups according to shared characteristics. Finding patterns and connections in the data without any prior understanding of its significance is the aim of clustering.
Our machine model discovers that this strategy is generally used to categorise data according to various patterns, including similarities or contrasts. Raw, unclassified data items are processed into groupings using these techniques. Since we haven’t supplied output parameter values in the preceding image, for instance, this approach will be utilised to categorise customers according to the input parameters that our data provides.
Some common clustering algorithms:
- K-means Clustering: Groups data into K clusters based on how close the points are to each other.
- Hierarchical Clustering: Creates clusters by building a tree step-by-step, either merging or splitting groups.
- Density-Based Clustering (DBSCAN): Finds clusters in dense areas and treats scattered points as noise.
- Mean-Shift Clustering: Discovers clusters by moving points toward the most crowded areas.
- Spectral Clustering: Groups data by analyzing connections between points using graphs.
2. Association Rule Learning
In unsupervised machine learning, association rule learning—also referred to as association rule mining—is a popular method for finding associations. This method is a rule-based machine learning methodology that identifies some really helpful relationships between a vast data set’s parameters. This method is mostly applied to market basket analysis, which aids in a deeper comprehension of the connections among various items.
For instance, depending on consumer behaviour, retail establishments employ algorithms based on this method to determine the correlation between the sales of one product and those of another. For example, if a consumer purchases milk, he could also purchase bread, eggs, or butter. When properly taught, these models may be used to prepare various offers and boost sales.
Some common Association Rule Learning algorithms:
- Apriori Algorithm: Finds patterns by exploring frequent item combinations step-by-step.
- FP-Growth Algorithm: An Efficient Alternative to Apriori. It quickly identifies frequent patterns without generating candidate sets.
- Eclat Algorithm: Uses intersections of itemsets to efficiently find frequent patterns.
- Efficient Tree-based Algorithms: Scales to handle large datasets by organizing data in tree structures.
3. Dimensionality Reduction
The technique of lowering a dataset’s feature count while maintaining the greatest amount of information is known as dimensionality reduction. Data visualisation and machine learning algorithm performance may both be enhanced using this method.
Consider a dataset that contains 100 student attributes, such as height, weight, grades, etc. Reducing it to just two features—height and grades—allows you to concentrate on important characteristics and facilitates data visualisation and analysis.
Here are some popular Dimensionality Reduction algorithms:
- Principal Component Analysis (PCA): Reduces dimensions by transforming data into uncorrelated principal components.
- Linear Discriminant Analysis (LDA): Reduces dimensions while maximizing class separability for classification tasks.
- Non-negative Matrix Factorization (NMF): Breaks data into non-negative parts to simplify representation.
- Locally Linear Embedding (LLE): Reduces dimensions while preserving the relationships between nearby points.
- Isomap: Captures global data structure by preserving distances along a manifold.
Challenges of Unsupervised Learning
Why Unsupervised Machine Learning Matters
- Noisy Data: Patterns can be distorted and algorithms’ efficacy diminished by outliers and noise.
- Algorithms frequently make assumptions (such cluster shapes) that could not correspond to the real data structure.
- Overfitting Risk: When models identify noise in the data rather than significant patterns, overfitting may take place.
- Limited Guidance: It is more difficult to direct the algorithm towards certain results when labels are missing.
- Cluster Interpretability: Findings like clusters could not make sense or fit into existing categories.
- Sensitivity to Parameters: A lot of algorithms, like k-means, need precise hyperparameter tweaking, such the number of clusters.
- Absence of Ground Truth: Since unsupervised learning does not use labelled data, it is challenging to assess the precision of the outcomes.
Applications of Unsupervised Machine Learning:
Unsupervised learning has diverse applications across industries and domains. Key applications include:
- Customer Segmentation: Algorithms cluster customers based on purchasing behavior or demographics, enabling targeted marketing strategies.
- Anomaly Detection: Identifies unusual patterns in data, aiding fraud detection, cybersecurity, and equipment failure prevention.
- Recommendation Systems: Suggests products, movies, or music by analyzing user behavior and preferences.
- Image and Text Clustering: Groups similar images or documents for tasks like organization, classification, or content recommendation.
- Social Network Analysis: Detects communities or trends in user interactions on social media platforms.
- Astronomy and Climate Science: Classifies galaxies or groups weather patterns to support scientific research.
READ MORE ABOUT UNSUPERVISED LEARNING ON : Wikipedia