Introduction
Data cleaning in machine learning pipeline is a crucial preprocessing step that involves identifying and removing missing, duplicate, or irrelevant data.
Raw data (such as log files, transactions, or audio/video recordings) is often noisy, incomplete, and inconsistent, which can reduce the accuracy of machine learning models.
The goal of data cleaning is to ensure datasets are accurate, consistent, and free of errors, which enhances Exploratory Data Analysis (EDA) and improves overall ML model performance.
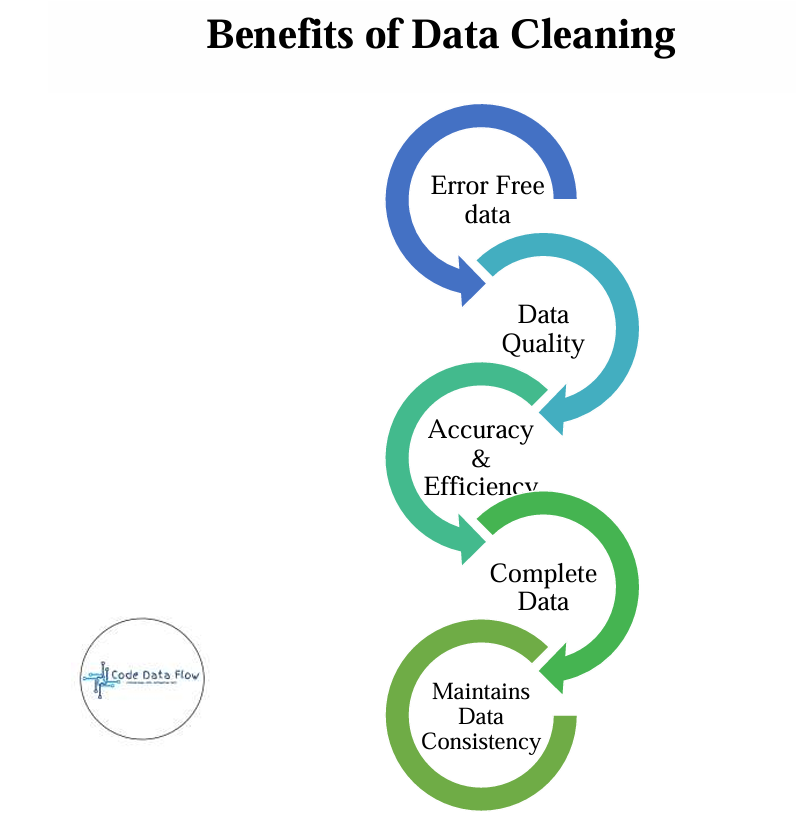
Benefits of Data Cleaning in Machine Learning Pipeline
- Improved model performance – Models learn better from clean datasets.
- Increased accuracy – Ensures error-free, consistent data.
- Better representation of data – Highlights true patterns and relationships.
- Improved data quality – Makes datasets reliable and trustworthy.
- Enhanced data security – Identifies and removes sensitive or confidential data.
How to Perform Data Cleaning in Machine Learning
The data cleaning process starts with identifying common issues like missing values, duplicates, and outliers.
Key Steps:
- Remove Unwanted Observations – Eliminate duplicates or irrelevant data.
- Fix Structural Errors – Standardize formats and variable types.
- Manage Outliers – Detect and handle extreme values.
- Handle Missing Data – Use imputation, deletion, or advanced techniques.
Implementation of Data Cleaning with Titanic Dataset
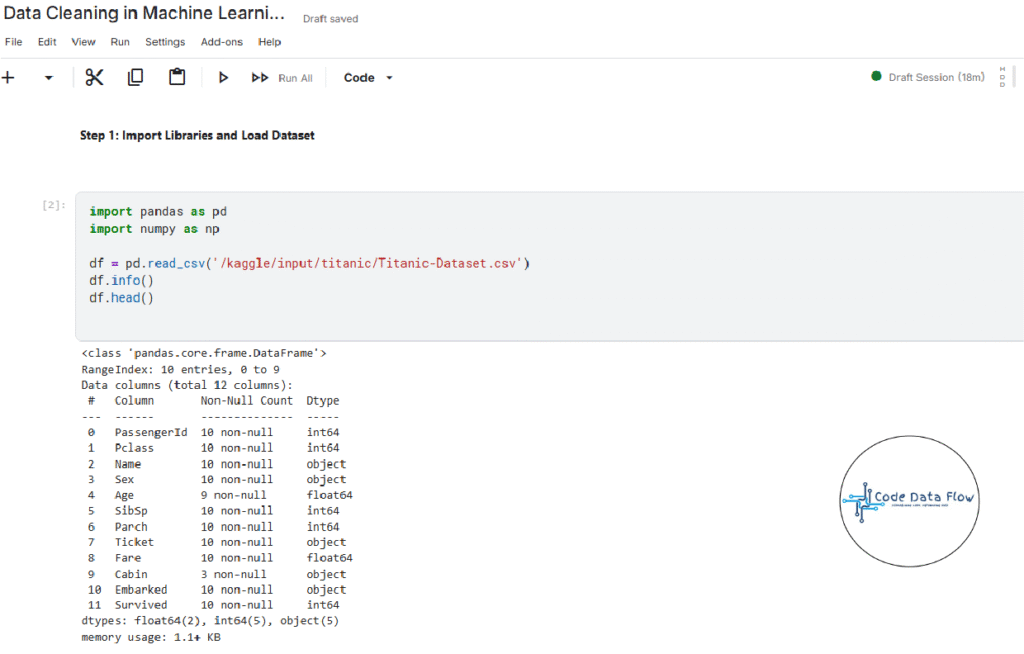
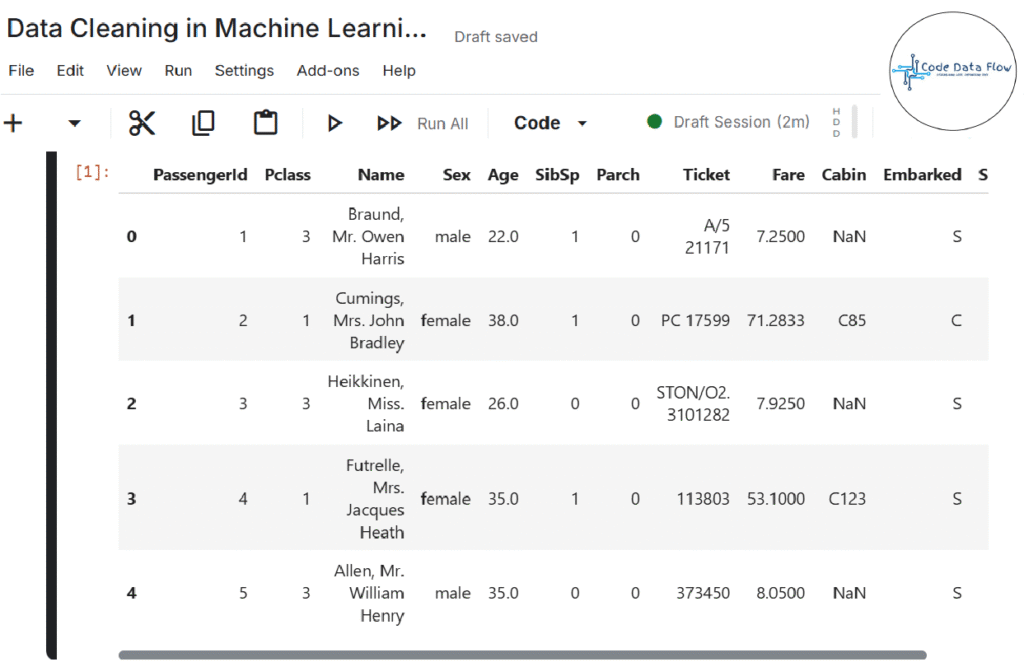
Step 1: Import Libraries and Load Dataset:
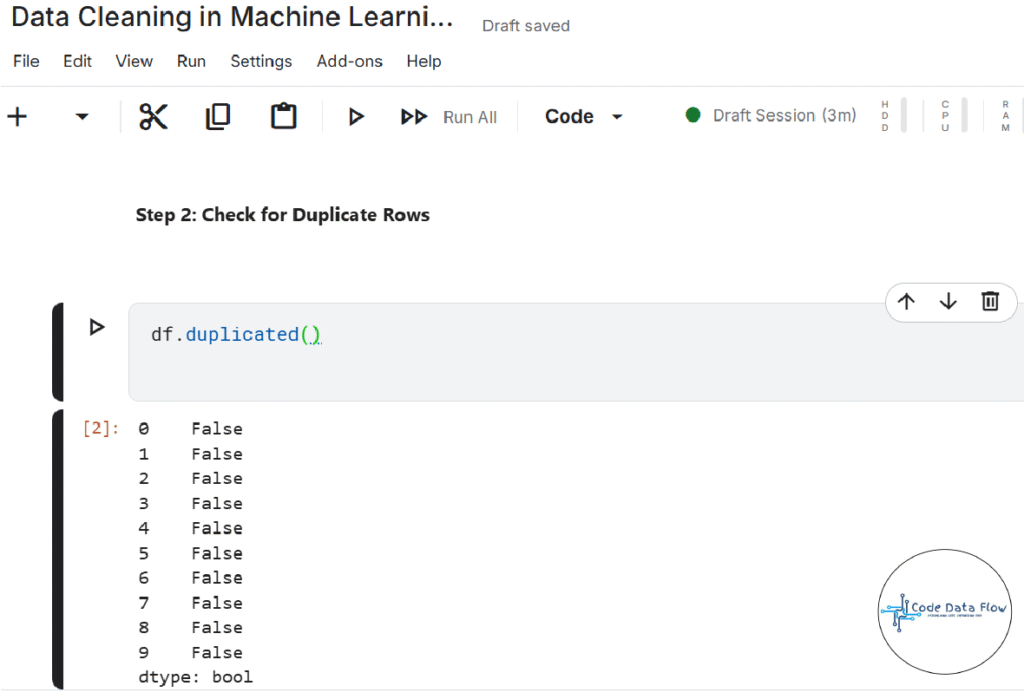
Step 2: Check for Duplicate Rows:
Step 3: Identify Categorical & Numerical Columns:
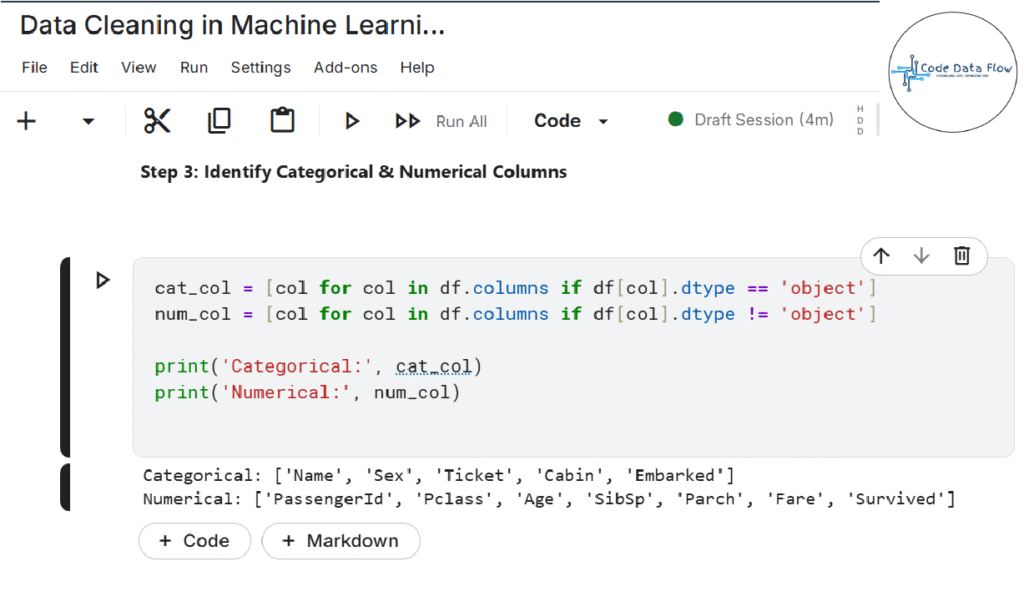
Step 4: Count Unique Values in Categorical Columns:
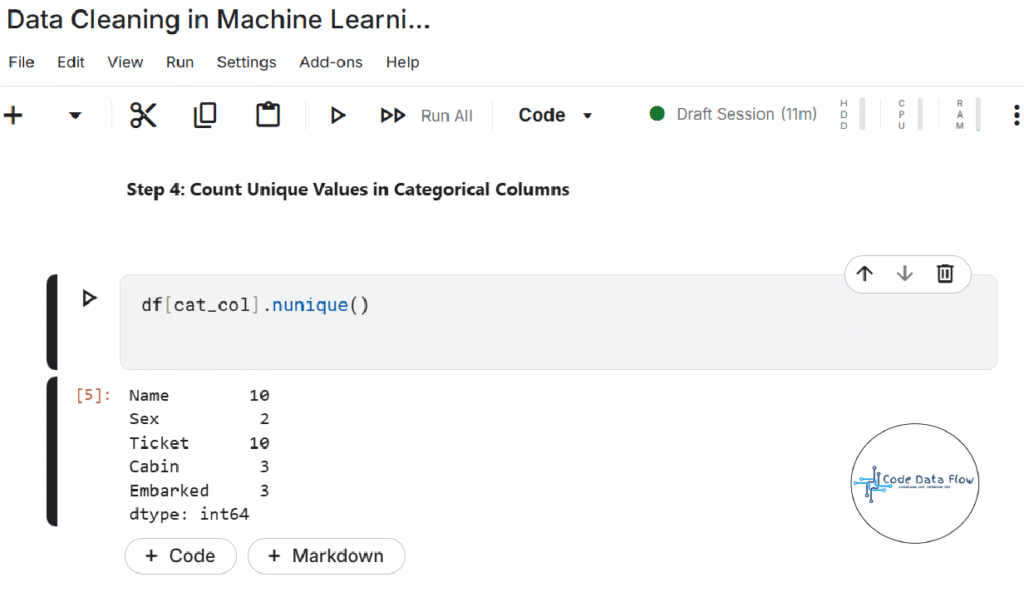
Step 5: Calculate Missing Values as Percentage:
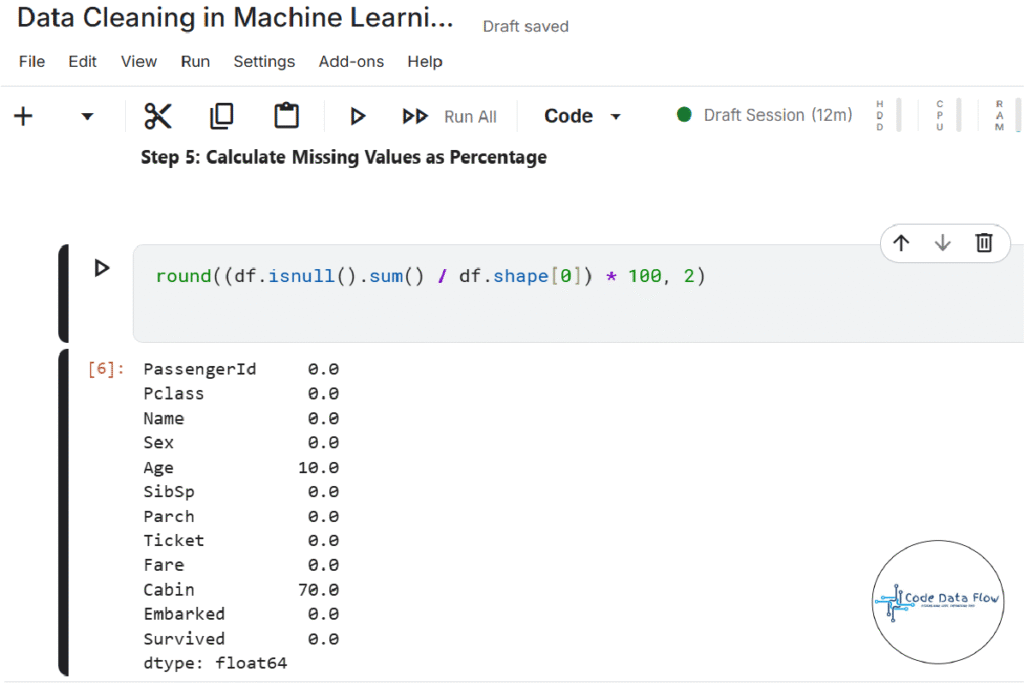
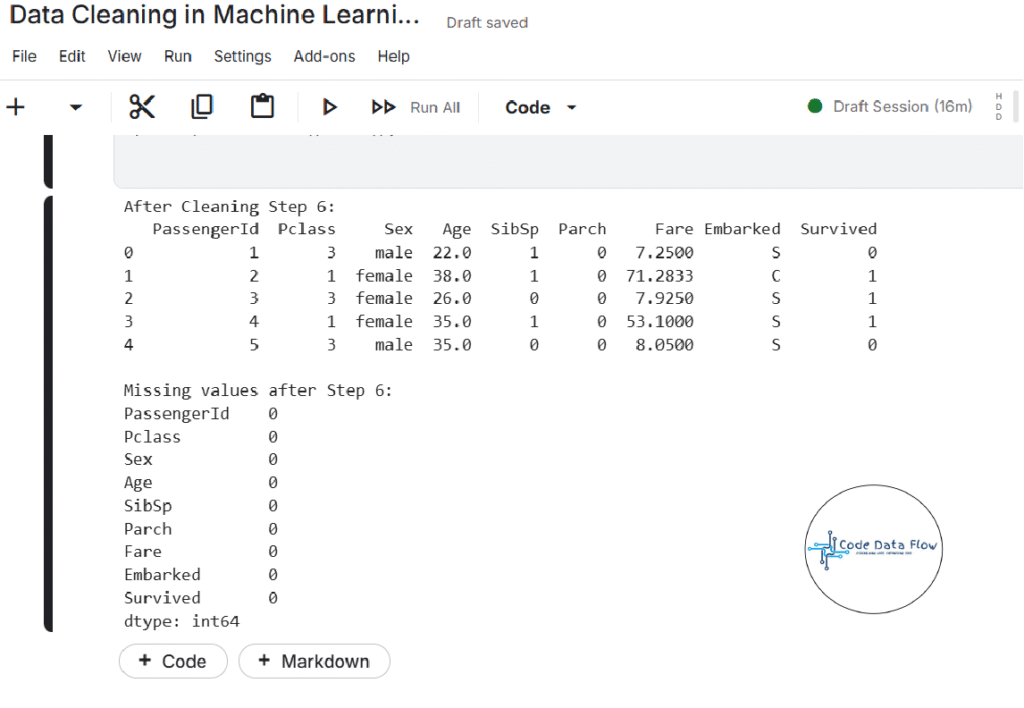
Step 6: Drop Irrelevant or Data-Heavy Missing Columns
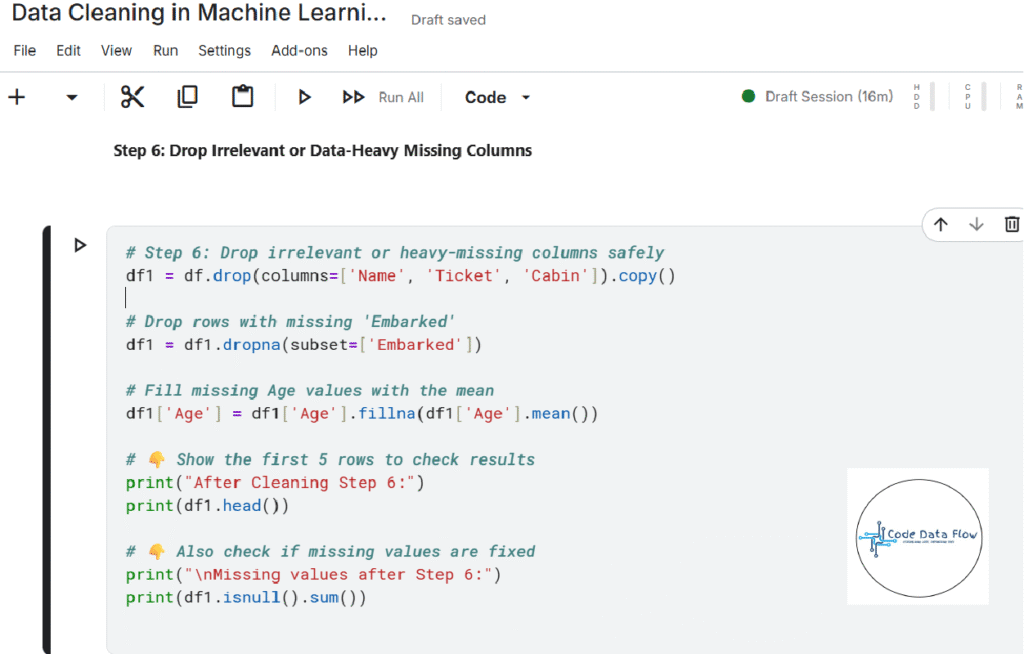
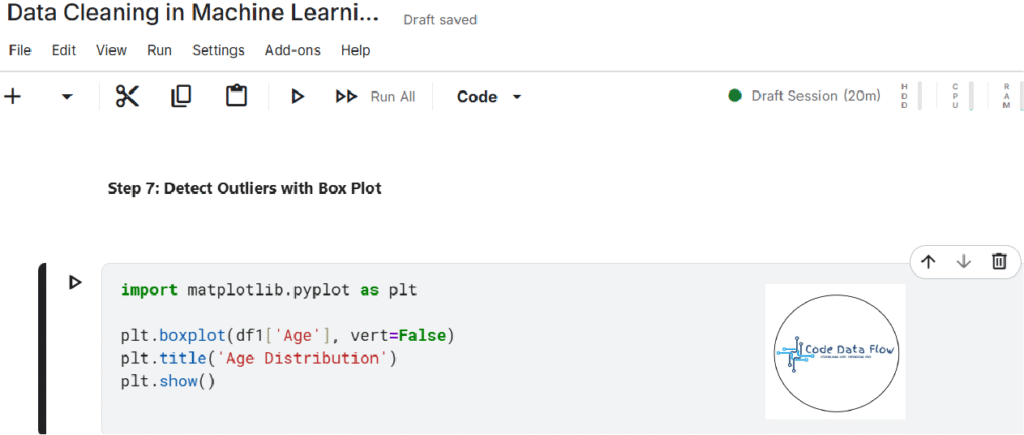
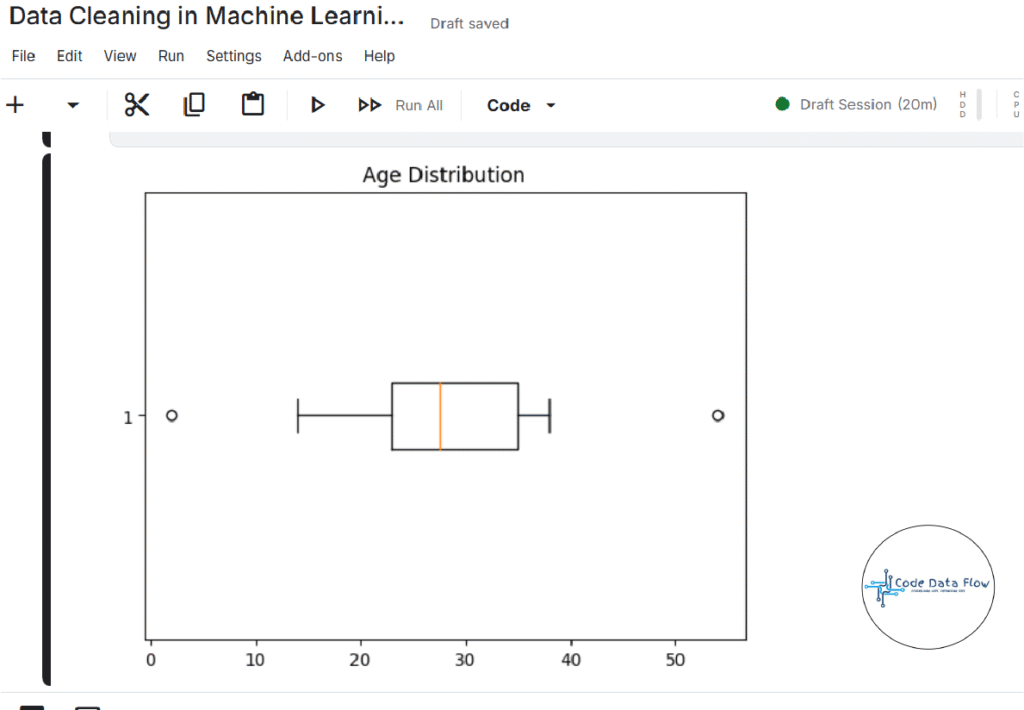
Step 7: Detect Outliers with Box Plot
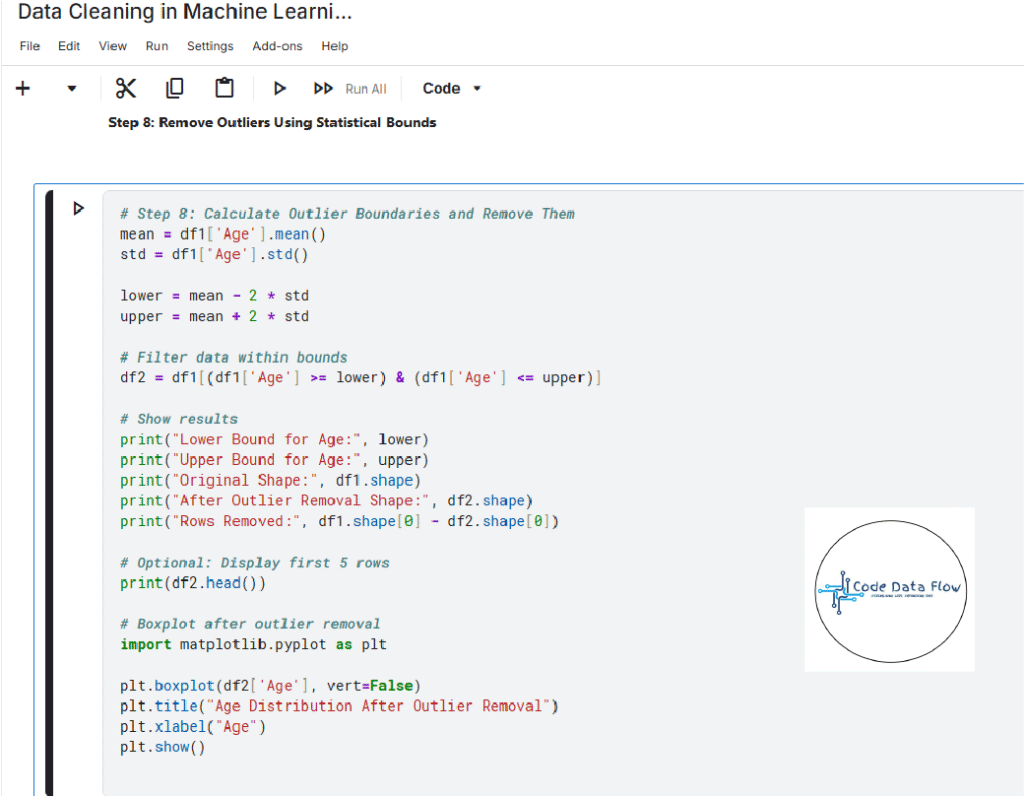
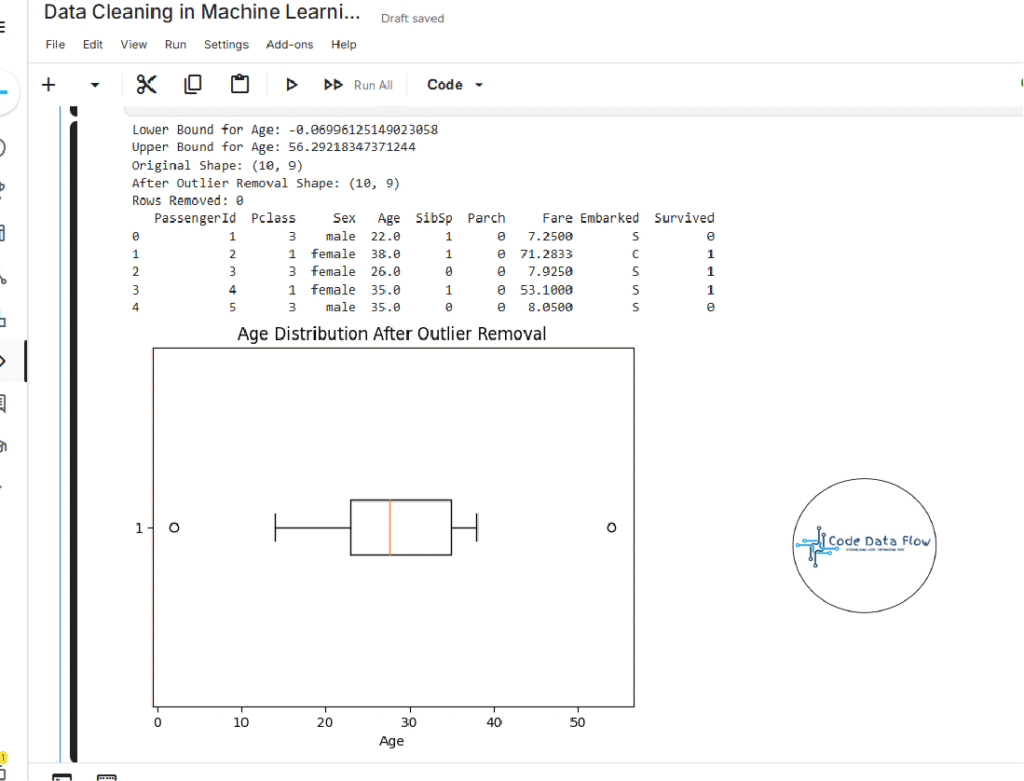
Step 8: Remove Outliers Using Statistical Bounds
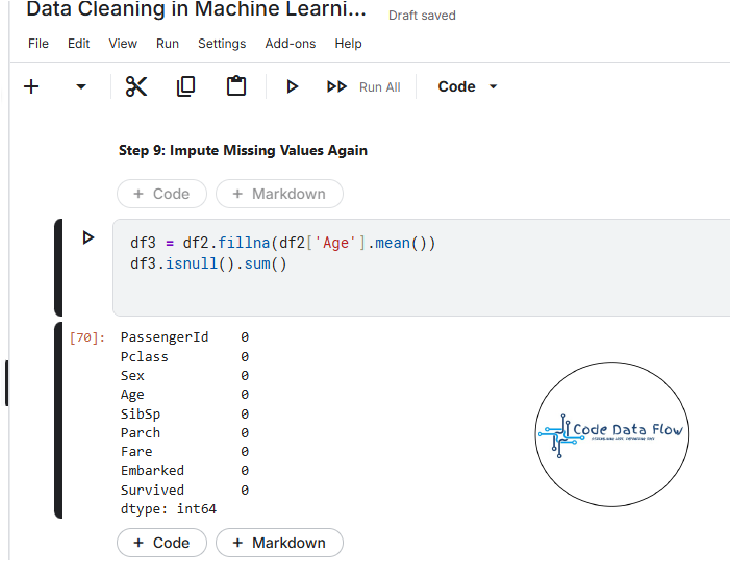
Step 9: Impute Missing Values Again
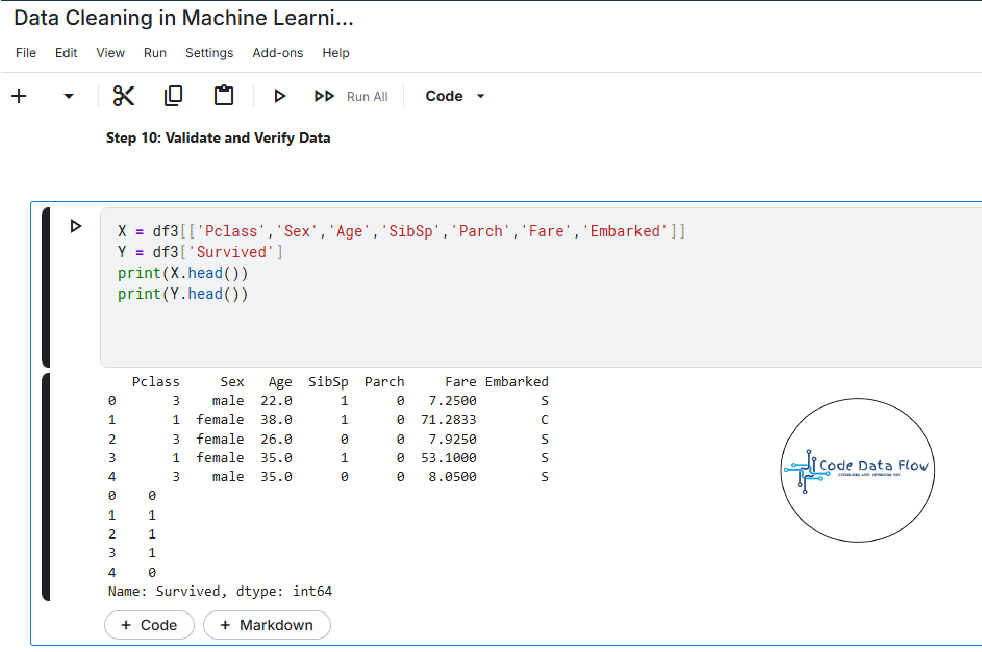
Step 10: Validate and Verify Data
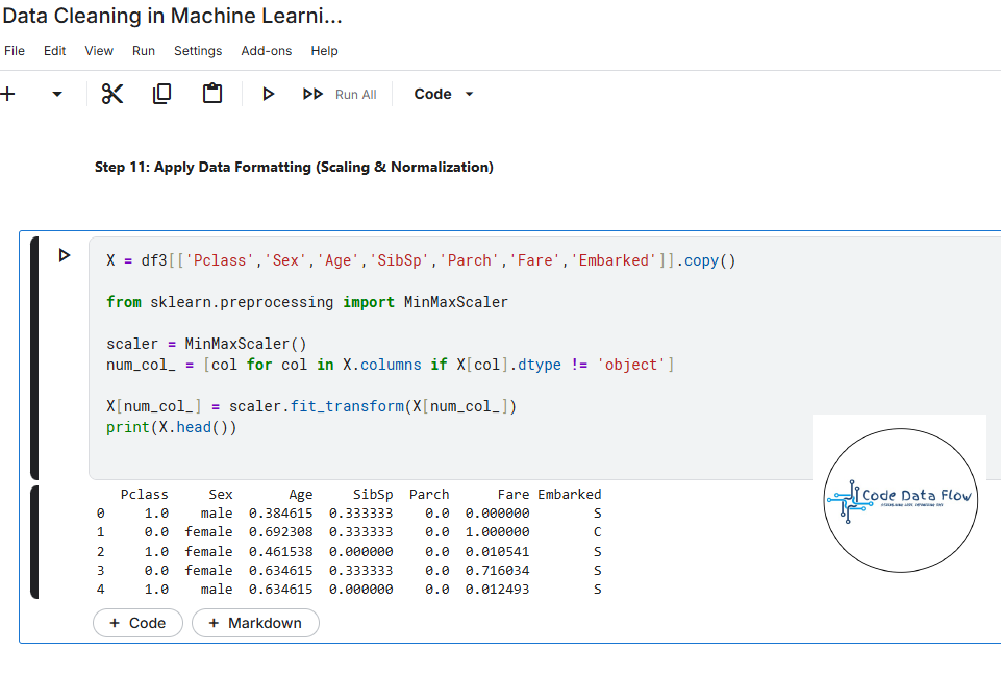
Step 11: Apply Data Formatting (Scaling & Normalization)
Popular Data Cleaning Tools for Machine Learning:
OpenRefine – Free & open-source data cleaning tool.
Trifacta Wrangler – AI-powered transformation platform.
TIBCO Clarity – Enterprise-grade profiling & cleansing tool.
Cloudingo – Specialized in deduplication for CRMs.
IBM InfoSphere QualityStage – Large-scale data quality management.
Advantages of Data Cleaning in ML Pipeline:
- Improved accuracy & reliability
- Better interpretability in EDA
- Enhances model performance
- Reduces bias from dirty data
Disadvantages of Data Cleaning:
- Time-consuming for large datasets
- Risk of data loss if not done carefully
- Resource-intensive requiring tools & expertise
- Can cause overfitting if too much data is removed
Conclusion:
Data cleaning in machine learning pipeline is the foundation of building reliable, accurate, and scalable AI systems. A well-cleaned dataset ensures better model performance, meaningful EDA, and actionable insights. While it may be time-intensive, the benefits outweigh the effort, making it an essential step in any ML project.