The process that provides organised guidance for the creation and implementation of machine learning models is known as the machine learning lifecycle. It involves a number of steps. For the machine learning model to be successful and functional, each step is essential. We can tackle complicated issues, obtain data-driven insights, and develop scalable and sustainable models by adhering to the machine learning lifecycle. The actions are:
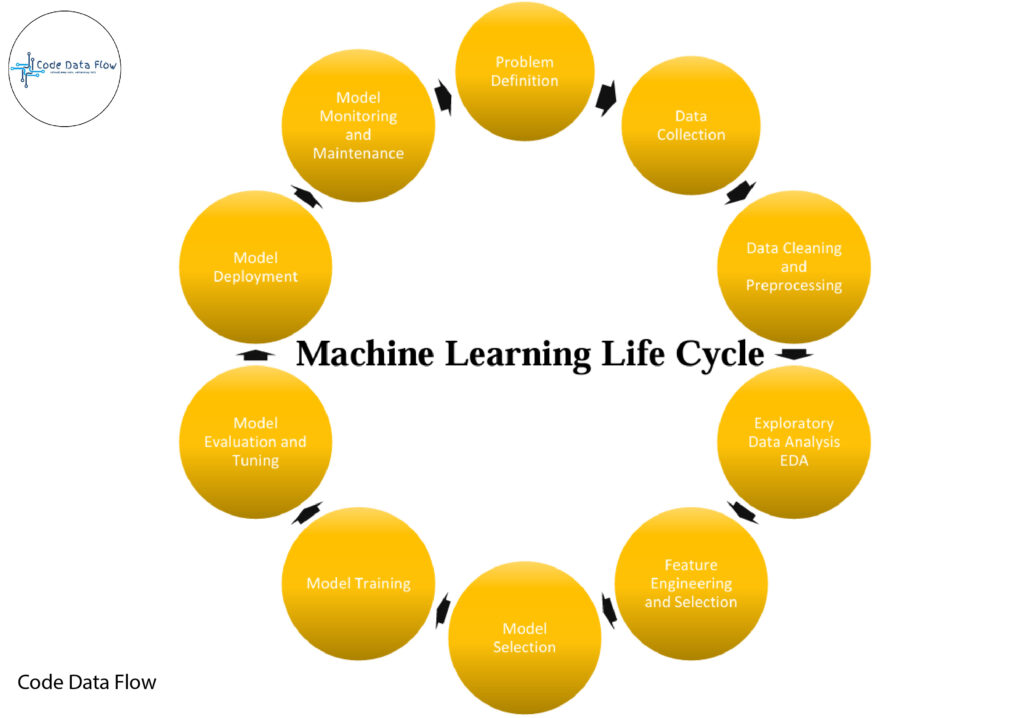
- Problem Definition
- Data Collection
- Data Cleaning and Preprocessing
- Exploratory Data Analysis (EDA)
- Feature Engineering and Selection
- Model Selection
- Model Training
- Model Evaluation and Tuning
- Model Deployment
- Model Monitoring and Maintenance
Machine Learning Lifecycle: From Idea to Deployment
The Machine Learning (ML) lifecycle is the structured process of turning raw data and a problem statement into a fully functional, real-world AI solution.
It moves step-by-step — from defining the problem to deploying the model — ensuring accuracy, reliability, and long-term usability.
Step 1: Problem Definition
Understanding the issue you’re attempting to address is the most crucial step before beginning any code or data work.
This phase establishes the framework for the entire undertaking.
Key Actions:
- Collaborate with stakeholders to fully understand business needs.
- Clarify project objectives, desired outcomes, and the scope of work.
- Frame the problem in detail to guide all future ML steps.
Step 2: Data Collection
After identifying the issue, the following stage is to collect high-quality, pertinent data.
The foundation of any machine learning effort is the appropriate data.
Key Actions:
- Ensure relevance — data must match the defined problem.
- Maintain quality — accurate, ethical, and trustworthy sources.
- Ensure quantity — enough data for robust training.
- Promote diversity — include various scenarios to improve generalization.
Step 3: Data Cleaning & Preprocessing
Rarely is raw data prepared for modelling. During this stage, unstructured datasets are transformed into a machine-readable format.
Key Actions:
- Data Cleaning: Handle missing values, remove duplicates, and fix inconsistencies.
- Preprocessing: Standardize formats, scale values, and encode categorical variables.
- Quality Assurance: Ensure the dataset is reliable for meaningful analysis.
Step 4: Exploratory Data Analysis (EDA)
Finding hidden patterns and insights in the data is the goal of EDA.
Before modelling, you may gain a deeper understanding of your dataset by using statistics and visualisations.
Key Actions:
- Use visual and statistical tools to explore data.
- Identify patterns, trends, and anomalies.
- Gain insights that guide feature engineering and model selection.
Step 5: Feature Engineering & Selection
Better models have better features.
The creation or selection of factors that have the greatest influence on forecasts is the main goal of this stage.
Key Actions:
- Feature Engineering: Create new features or transform existing ones.
- Feature Selection: Keep only the most relevant variables.
- Optimization: Reduce complexity while boosting accuracy.
- Domain Expertise: Leverage subject knowledge for better feature creation.
Step 6: Model Selection
To get the greatest results, selecting the appropriate algorithm is essential.
Key Actions:
- Match the model to your problem type and dataset.
- Consider complexity, interpretability, and scalability.
- Experiment with multiple algorithms before finalizing.
Step 7: Model Training
This is where the chosen model learns from historical data.
Key Actions:
- Train using labeled datasets to identify patterns and relationships.
- Use an iterative process to adjust parameters.
- Optimize for accuracy and generalization.
- Validate with unseen data to ensure real-world reliability.
Step 8: Model Evaluation & Tuning
The model is evaluated to make sure it performs as expected.
Adjust the settings as necessary to enhance the outcomes.
Key Actions:
- Measure performance using metrics like Accuracy, Precision, Recall, and F1-score.
- Identify strengths and weaknesses.
- Adjust hyperparameters to enhance predictions.
- Repeat until the model is robust and reliable.
Step 9: Model Deployment
Taking the model into the actual world, where it can provide predictions and provide value, is the last phase.
Key Actions:
- Integrate the model into business systems.
- Use predictions for informed decision-making.
- Monitor performance and update regularly for continued accuracy.
Conclusion
The machine learning lifecycle is a continuous and adaptive process.
From problem definition to deployment, every step is vital to building models that deliver real-world impact.
By following this structured approach, organizations can transform complex challenges into data-driven solutions.